What The WorkPaper Benchmark Proves
Status: public benchmark explainer for @bilig/headless
This page is the short, shareable version of the WorkPaper benchmark claim. It turns checked-in artifacts into a plain-English evaluation guide without inflating what the benchmark can prove.
The Claim
The all-provider source of truth is
packages/benchmarks/baselines/headless-performance-leadership-scorecard.json.
The short artifact name is headless-performance-leadership-scorecard.json.
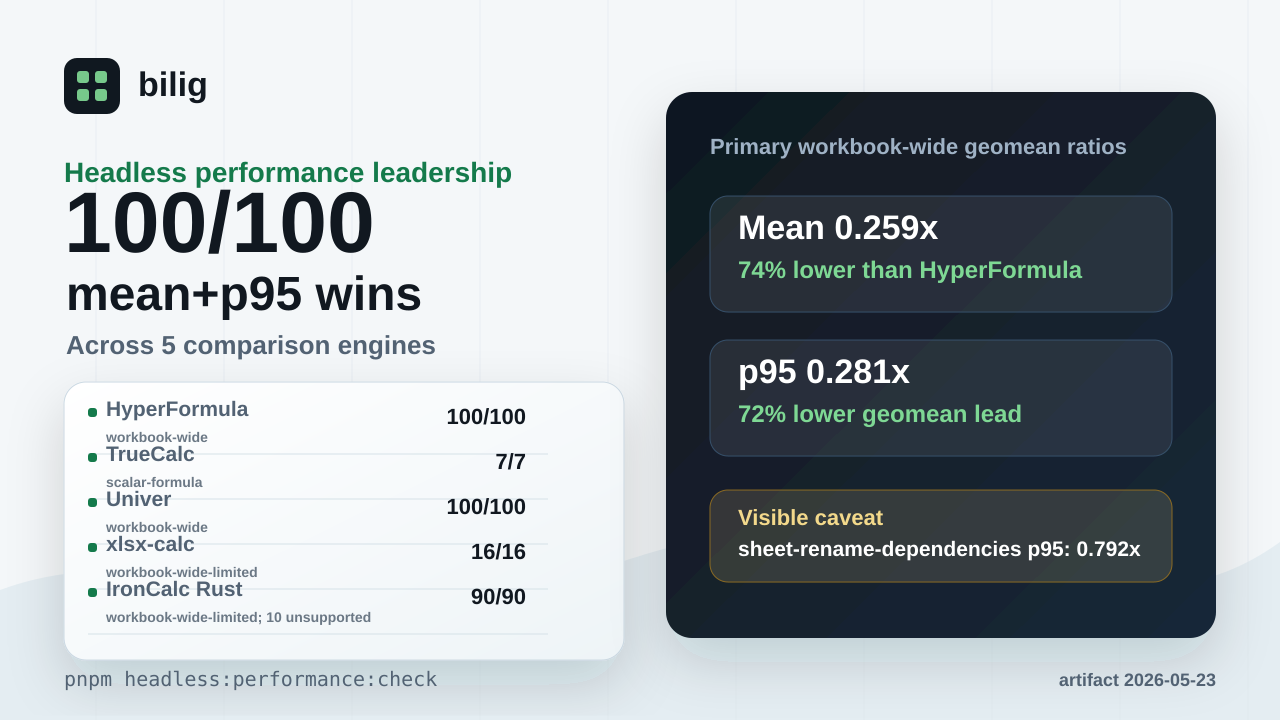
It currently reports goal status achieved: 100/100 comparable workloads win
on both mean and p95 latency across 5 comparison engines and 2 workbook-wide engines.
Comparison engines: HyperFormula, TrueCalc, Univer, xlsx-calc, IronCalc Rust.
| Provider | Coverage tier | Mean+p95 wins | Mean wins | p95 wins | Mean geomean ratio | p95 geomean ratio | Unsupported |
|---|---|---|---|---|---|---|---|
| HyperFormula | workbook-wide | 100/100 |
100/100 |
100/100 |
0.2586x |
0.2807x |
0 |
| Univer | workbook-wide | 100/100 |
100/100 |
100/100 |
0.0028x |
0.0034x |
0 |
| IronCalc Rust | workbook-wide-limited | 90/90 |
90/90 |
90/90 |
0.124x |
0.1686x |
10 unsupported |
| xlsx-calc | workbook-wide-limited | 16/16 |
16/16 |
16/16 |
0.0839x |
0.0786x |
0 |
| TrueCalc | scalar-formula | 7/7 |
7/7 |
7/7 |
0.1837x |
0.2359x |
0 |
Ratios below 1.0x mean WorkPaper is faster on that metric. The table is not
hand-maintained marketing copy; pnpm public:evidence:check verifies it against
the checked artifacts.
Artifact Links
- HyperFormula:
packages/benchmarks/baselines/workpaper-vs-hyperformula.json - Univer:
packages/benchmarks/baselines/workpaper-vs-univer.json - IronCalc Rust:
packages/benchmarks/baselines/workpaper-vs-ironcalc-rust.json - xlsx-calc:
packages/benchmarks/baselines/workpaper-vs-xlsx-calc.json - TrueCalc:
packages/benchmarks/baselines/workpaper-vs-truecalc.json
Primary Workbook-Wide Lane
The current checked-in WorkPaper-vs-HyperFormula artifact records WorkPaper
100/100 mean-latency wins on scorecard-eligible comparable workloads:
| Lane | Comparable Workloads | WorkPaper Mean Wins | HyperFormula Mean Wins |
|---|---|---|---|
| Overall | 100 |
100 |
0 |
| Public | 73 |
73 |
0 |
| Holdout | 27 |
27 |
0 |
The artifact was generated at 2026-05-23T17:51:04.599Z.
The overall directional mean-ratio geomean is 0.2586071973976171, and the
overall directional p95-ratio geomean is 0.2806672128213908. The headless
leadership scorecard records 100/100 workloads winning both mean and p95
against HyperFormula.
The current worst p95 row is sheet-rename-dependencies, where the current
WorkPaper-to-HyperFormula p95 ratio is 0.7917355369127405.
What It Proves
It proves that the checked-in WorkPaper runtime leads the current comparable headless benchmark suite on both mean and p95 latency for every comparable row represented in the all-provider scorecard.
The covered families include workbook build and rebuild paths, runtime restore from snapshot, sheet lifecycle, named expressions, dirty execution, batch edits, structural row and column edits, range reads, aggregations, conditional aggregation, and lookup workloads.
It also proves the public claim is auditable from the repository. The expected scorecard shape is checked by:
pnpm headless:performance:check
pnpm public:evidence:check
What It Does Not Prove
It does not prove that bilig is a complete Excel clone.
It does not prove full formula parity with Excel, Google Sheets, or every other formula engine.
It does not prove future p95 rows will stay faster after new workloads are added. The honest claim is that the checked headless runtime leads this comparable suite today, not that every future workbook shape is covered.
It does not count unsupported rows as wins. IronCalc Rust currently has 10
unsupported workload adapters recorded explicitly in its artifact.
It does not prove that browser-grid rendering, import/export, collaboration, or every user workload is faster. This benchmark is about the headless WorkPaper runtime path.
If the artifacts are regenerated and the scorecard changes, the public claim must change with them.
How To Verify
For the benchmark evidence, start with:
docs/headless-workpaper-benchmark-evidence.mdpackages/benchmarks/baselines/headless-performance-leadership-scorecard.jsondocs/public-evidence.jsondocs/assets/workpaper-benchmark-card.png- benchmark critique discussion
Run the checked gates:
pnpm workpaper:bench:competitive:check
pnpm workpaper:bench:univer:check
pnpm workpaper:bench:ironcalc-rust:check
pnpm workpaper:bench:xlsx-calc:check
pnpm workpaper:bench:truecalc:check
pnpm headless:performance:check
pnpm public:evidence:check
Shareable Copy
Short:
bilig’s WorkPaper benchmark currently records
100/100comparable workloads winning both mean and p95 across the all-provider headless performance scorecard. The public page names the providers, coverage tiers, artifacts, and unsupported rows.
Reply-sized:
the useful part is the audit trail: checked benchmark artifacts, verify commands, and public drift guards. the claim is not “faster at everything”; it is
100/100mean+p95 wins for the current comparable headless WorkPaper scorecard across HyperFormula, Univer, IronCalc Rust, xlsx-calc, and TrueCalc.